Here at Ad Hoc Labs we are open-sourcing one of the projects I started to handle reliable execution of different tasks.
I wanted to build a library that would:
- have a higher level of abstraction than queuing
- allow development of new types of tasks with only config changes
- be back-end independent, so backends like RabbitMQ and Kafka would work based on config
- allow flexibility to have publishers running in one project and consumers running in another
- allow flexibility to decide which projects run what consumers and producers and how many of them.
Our product Burner is a privacy layer for phone numbers. There are many things we want to run in a reliable manner, and we need to queue tasks and execute things in an asynchronous way. We are a Scala shop and among many Scala libraries we also use Akka.
In the Akka world, we have actor A sending a message to actor B. There are many things that can go wrong, even if both are running in same JVM. Actor B may be down when actor A is sending the message. Actor B may fail to process the task, so there is a need for retries. Some tasks can take long time to process, so there is a need to run things asynchronously. You may want to scale out and have many instances of actor B, etc.
This actor model is very clean and well-suited for this type of situation. And if you’re familiar with Akka, you know that Akka handles some of those cases out of the box, some via Akka persistence, and some things simply aren’t there.
So I wanted to have a very simple library that wouldn’t require a Cassandra cluster, force you to write a lot of boilerplate, or force the use one specific message queue – I wanted it to be extremely flexible and extendable.
The core idea is the same: actor A sends a task to actor B to process, and actor B will eventually get the task. It’s very similar to the way you send a message from actor A to actor B in Akka; there’s no other complexity there.
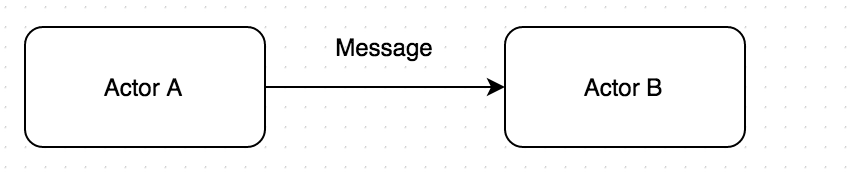
This is how messages are sent between two actors in Akka.
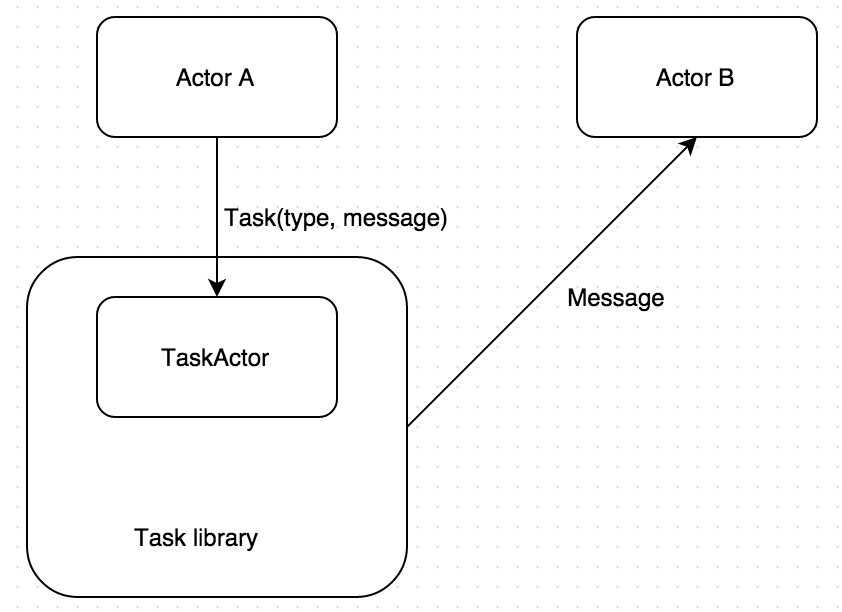
And this is how that same message is sent from actor A to actor B using Task
library. You just wrap it in Task envelope, specifying the type of task
(push message for example) and send it to TaskActor. Actor B will eventually
receive that message.
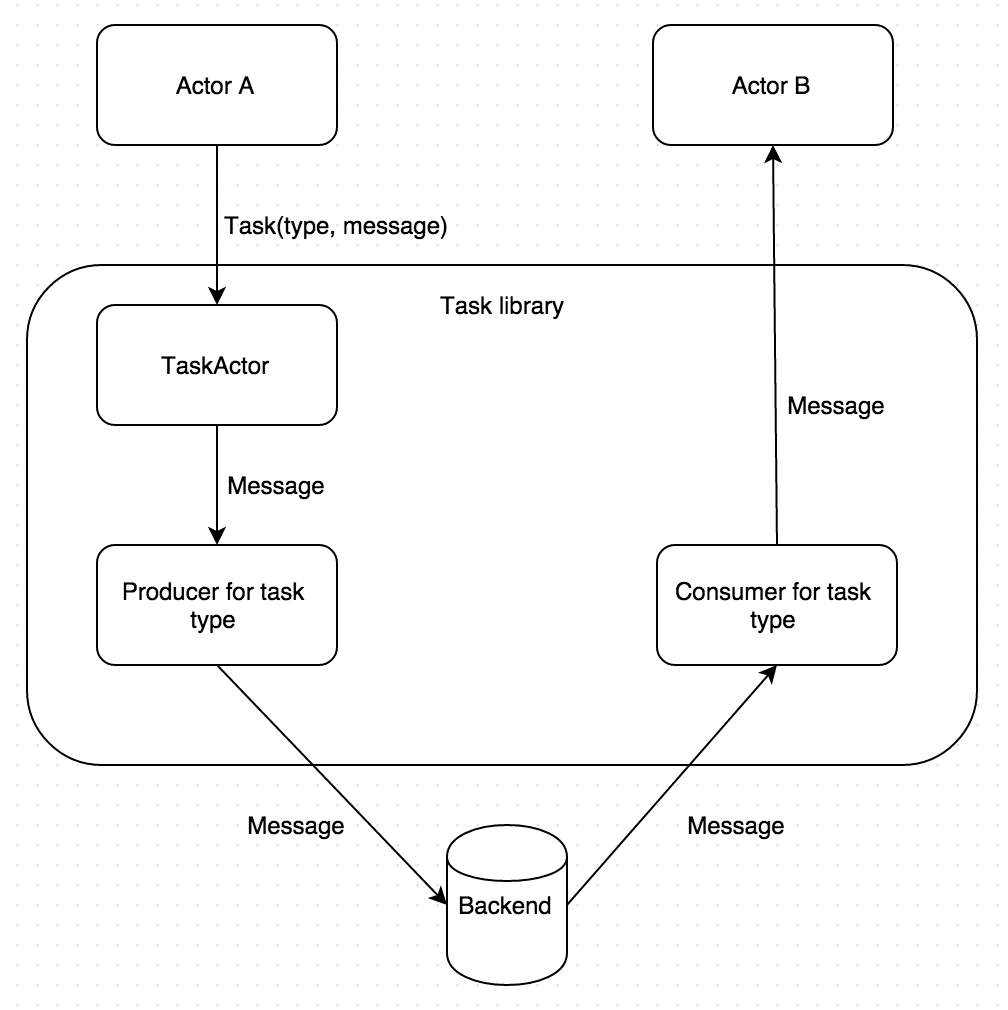
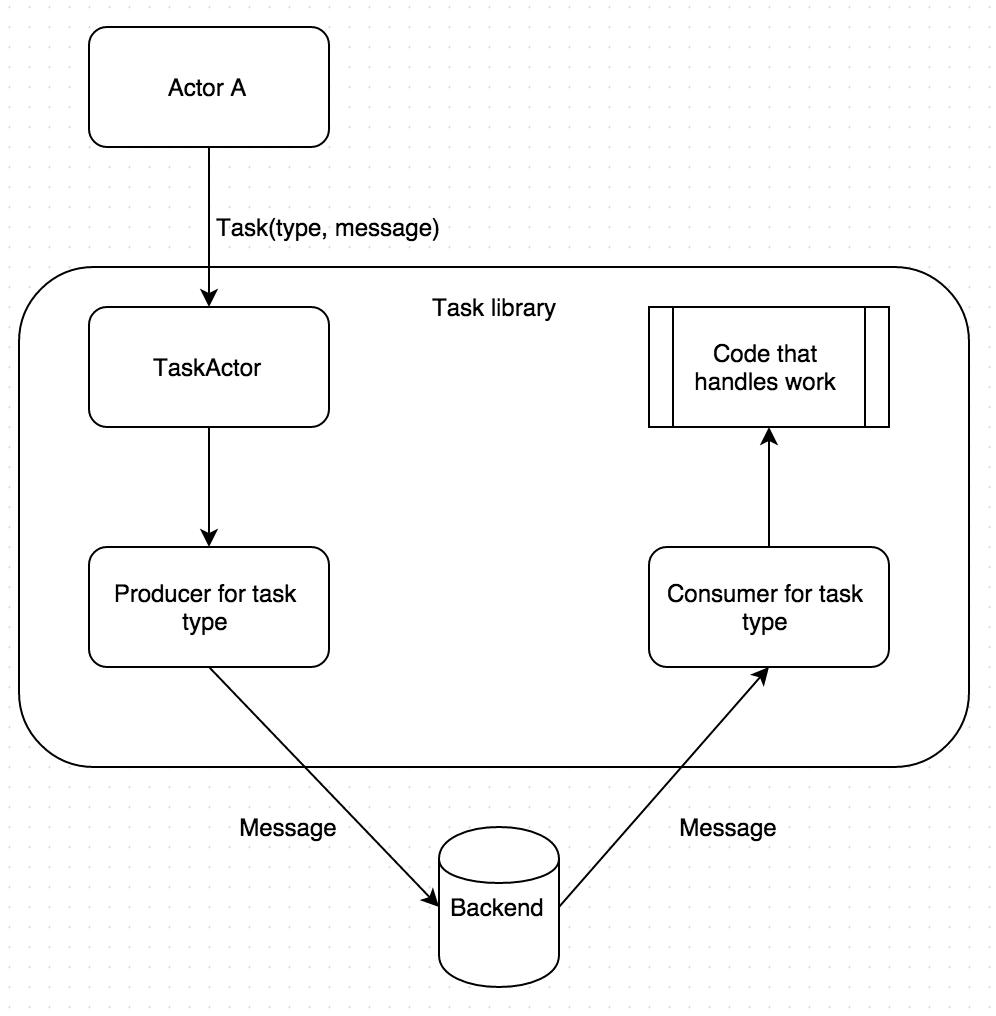
What’s happening under the hood is the following:
 Based on the configuration, where Task library is embedded, we specify the
producers and consumers the project will run. Here is an example config,
which specifies that this project is running sometask producer,
sometask consumer (running in the same project, for simplicity), and destination actor,
which is actor B.
Based on the configuration, where Task library is embedded, we specify the
producers and consumers the project will run. Here is an example config,
which specifies that this project is running sometask producer,
sometask consumer (running in the same project, for simplicity), and destination actor,
which is actor B.
This type of consumer is called proxy consumer since it’s not processing messages; it simply gets messages and forwards them to another actor (in this instance, Actor B) that will do the processing and respond. (We’ll see that there are consumers that process tasks on their own also.)
Once the response is successful, the consumer marks the task as successfully completed; if it fails some other consumer of the same type (most likely running on another box) will pick it up to process.
task {
producers = ["sometask"]
consumers = ["sometask"]
consumer-proxy-actors= {
sometask {
target-actor = "akka://my-system/user/actor-b"
}
}
}For all the producers and consumers specified in config, Task library will create consumer and producer actors which become children of TaskActor and are supervised by it. When TaskActor receives a Task message it forwards it to the right producers based on type of the task, specified in Task message. The actual message payload that’s in Task messages will be sent to the right queue (based on the task type) on the back end (RabbitMQ for example.) From there the consumer for that type, that’s listening on that queue, will receive the message, forward it to the actor specified in config, and mark that task as completed when the target actor finishes processing the message without failure. (A thing to note here is that we’re able to send any case class in a queued manner to any destination actor just by adding configuration.)
This is simple and clean, at least the user-facing part, although this is more of a generic model that enables implementation of any type of task. For more specific or repeated cases, such as sending push notifications, publishing analytics events, downloading files and storing them on s3, etc., you can simplify further by having regular consumers instead of proxy consumers. As an example, the consumer for push notifications, when getting a message, can send the push itself rather than forwarding it to another actor. And that’s what gives the library another vector of extensibility – developers can add this type of reusable consumers into the Task library itself, which will increase the number of things it’ll be able to do out of the box.
With this type of common task, all we need is:
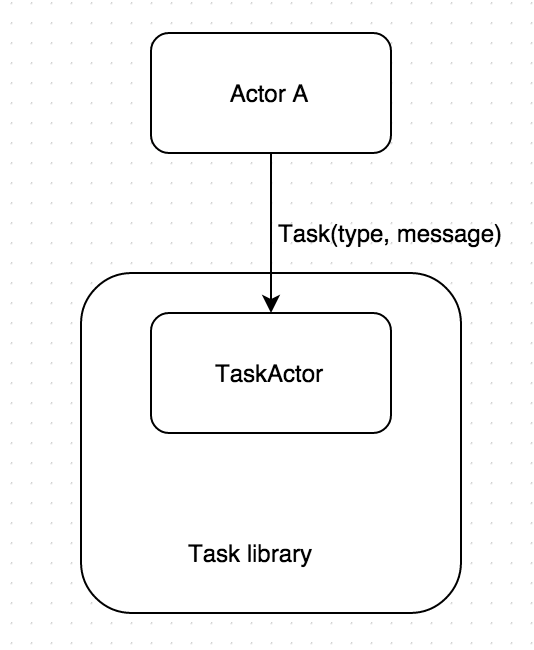
And under the hood it will do this:
Those are the features we have in current version of Ad Hoc Labs Task library. There are lot of other things I hope to build for it and open sourcing it was the first stage. I am hopeful other people will be excited about the library and will contribute.
My plan is to have Ad Hoc Labs version be the stable version and build all new features in my fork without worrying about backward compatibility. When version 1.0.0 is reached, I will merge back.
Some ideas on what I would like to build for v1.0.0:
- Implement Kafka and Redis backends. Right now only RabbitMQ is supported.
- Cleaner way to configure number of workers
- Retries
- More built-in consumers (Mixpanel, S3, etc.)
- Use Travis CI for builds, since Ad Hoc Labs Jenkins is private
- Artifacts to be published in Maven central, since Ad Hoc Labs Nexus is private
- Separate project for example code
- Long Term - Make the project relevant to non-Scala shops.
More about that – when you think about it there are two clear partitions there,
the publisher side and the consumer side.
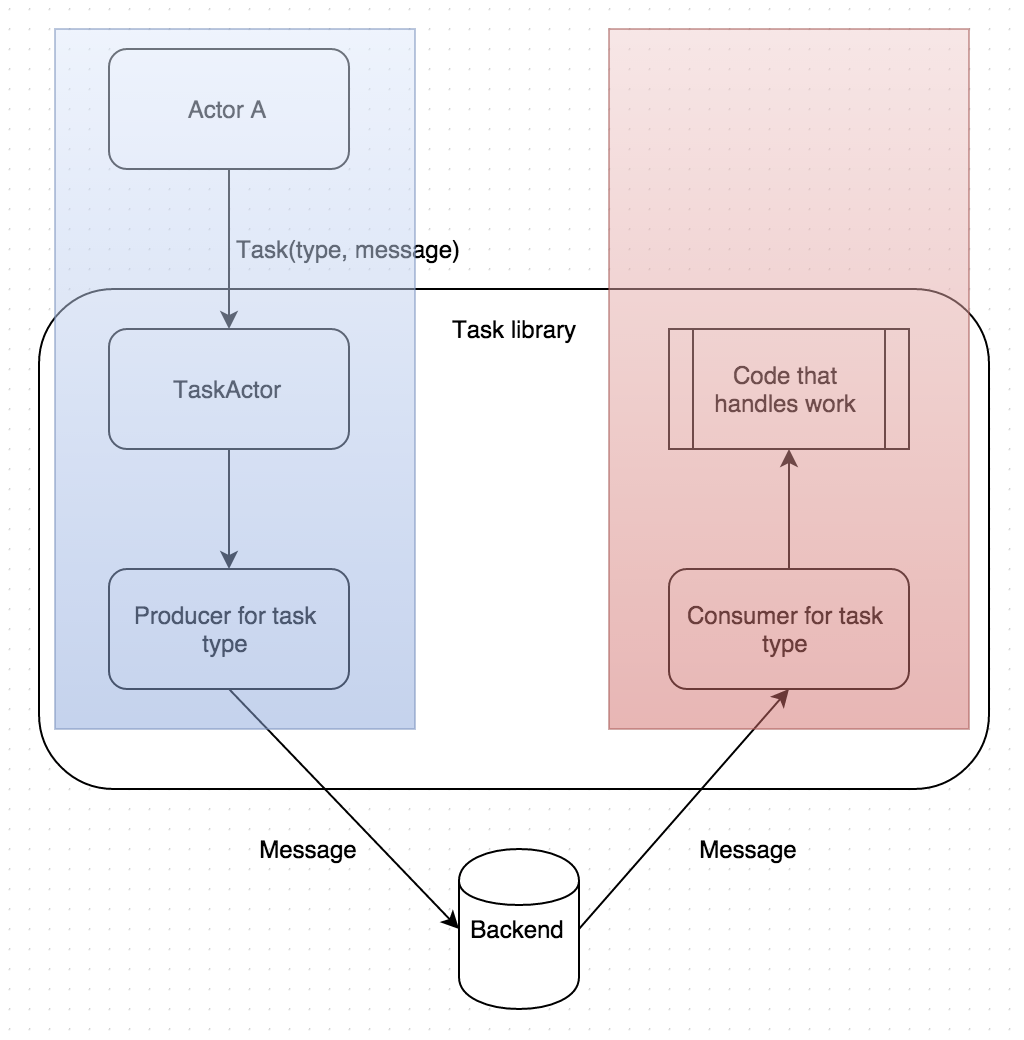
Built-in or common consumers will be built right into Task library and it’ll always be Scala.
The Producer side, however, doesn’t have to be Scala. As long as the message gets to the
backend and there is a predefined protocol for messages, task library workers can pick it
up and process the task.
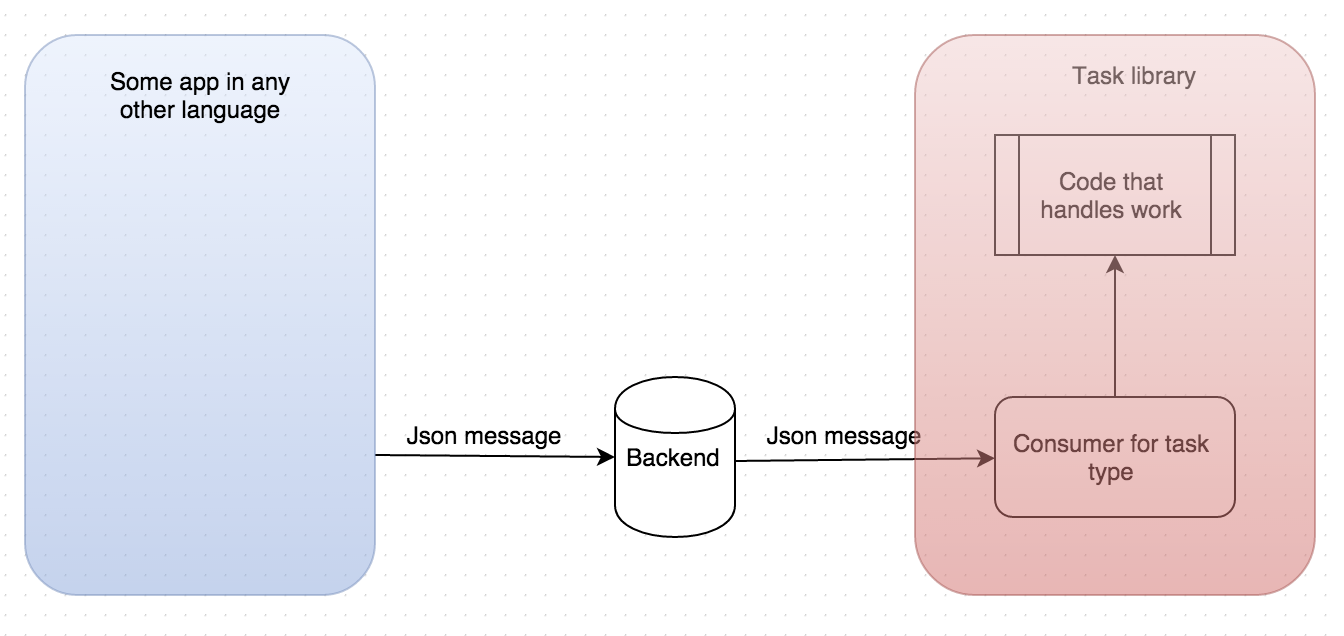
That would be a good idea if some people already have infrastructure that talks
to RabbitMQ or Kafka. A cleaner approach would be to put an HTTP layer on top of Task library, which would take the massages from REST layer and use publisher infrastructure that’s already in Task library. This way the backend would still be encapsulated and pluggable. A couple of servers can run the Task HTTP service behind a load balancer for producing, and a set of servers can run Task library directly as workers (which it already is able to do.)
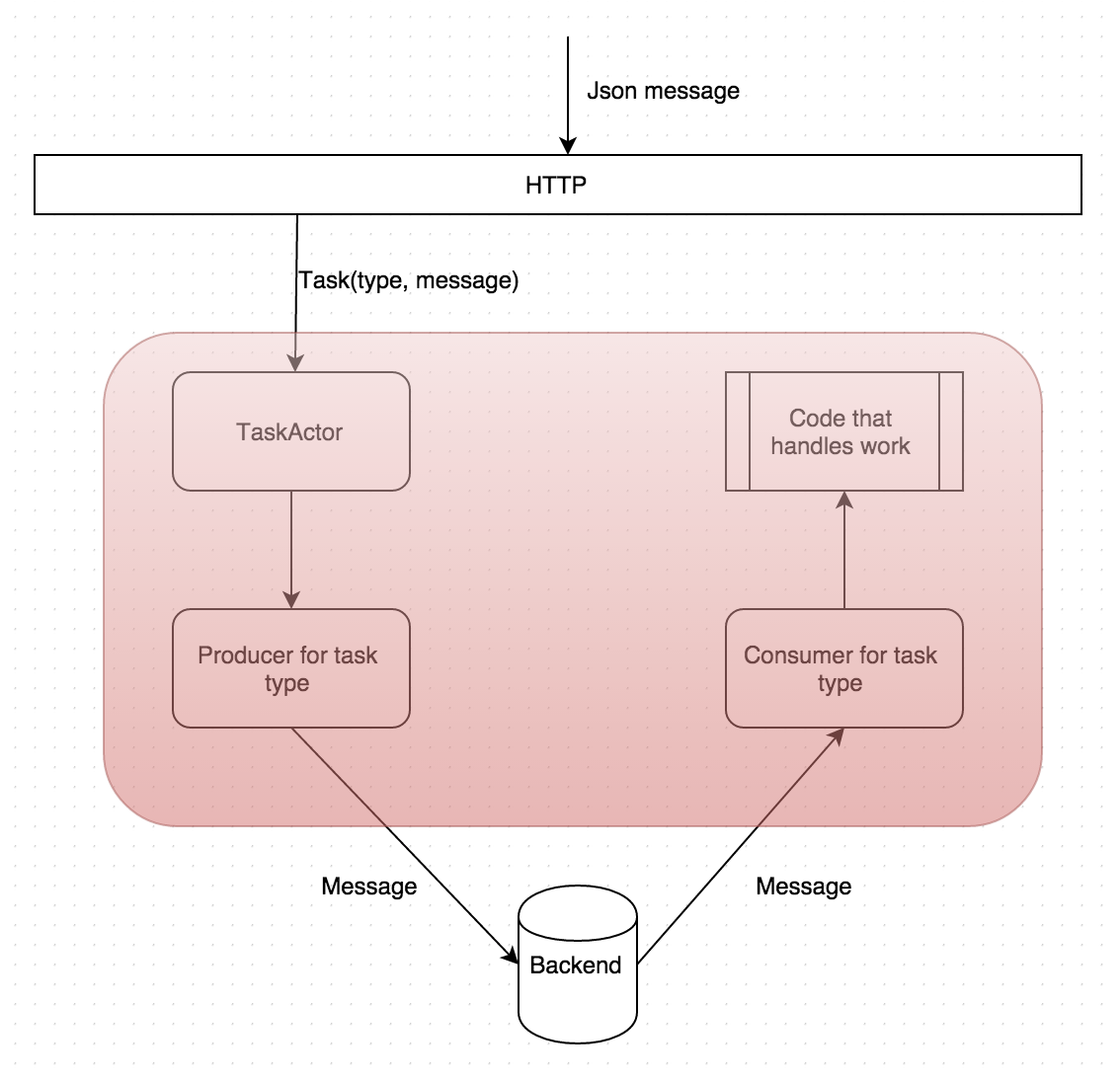
This would make the project go beyond being a nice Scala library, to a project that’s able to process common tasks in a reliable manner and can be used from any codebase written in any language. Current open items will be tracked in Github issues, and if you’re interested in contributing or have a question, feel free to jump into the Gitter room.