AWS Lambda supports writing handlers in Nodejs, Python and Java. The first two are really easy - if you don’t have any external dependencies and script is easy to write, you can even write your lambda in AWS console. However when it comes to Java, things get a little more complicated than that (not even talking about Scala yet.) So at the very least you’ll need to create a new project, know what jar dependencies to add for lambda, implement the handler method in a class that potentially implements some interface, know how to generate a deployment package (fat jar or a zip file for java projects), upload to S3 (since that jar would have a decent size), etc. If I want to implement my lambda in Scala now, I would have to deal with all those complexities for Java projects and more - such as more dependencies, how to write an actual Scala code (not Java in Scala syntax), interoperability, immutability, built in features like case classes, futures, etc. I thought it’s not fair for Scala developers and things can be much simpler (maybe not Nodejs simple) but at least it has to be simpler than doing in Java, since we all know Scala has more things to make developer’s job easier.
So what if every time I need a lambda in Scala, I just generate a project that has all the dependencies that are needed, all the plumbing needed, a way to upload to S3 from SBT, etc? Luckily, this is a solved problem, I can just create an activator template and use the activator to generate a project from that template every time I need one.
The second issue would be interoperability. AWS expects a certain interface - if all that you are doing is primitives or using built in classes that amazon created for events (like S3, SNS, etc, see aws-lambda-java-events jar), then it’s not a big problem, but if my lambda takes a JSON input and responds with a JSON output things get a little tricky.
The Problem
Let’s first see what AWS has for Java projects. From Amazon’s documentation, you can define a lambda like this:
package example;
import com.amazonaws.services.lambda.runtime.Context;
public class Hello {
public String myHandler(String name, Context context) {
return String.format("Hello %s.", name);
}
}Where our handler function would be example.Hello::myHandler
We can easy implement this in Scala as:
package example;
import com.amazonaws.services.lambda.runtime.Context;
object Hello extends App {
def myHandler(name: String, context: Context): String = s"Hello $name"
}Nothing special is needed. The reason is that myHandler is taking name: String parameter and returning a String. Both are Java primitives and AWS understands it well.
In real life, things would be little more complicated. You may want your handler to take any JSON and respond with a primitive or a JSON. Let’s look at what they have for Java again:
package example;
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
public class HelloPojo implements RequestHandler<RequestClass, ResponseClass> {
public ResponseClass handleRequest(RequestClass request, Context context) {
String greetingString = String.format("Hello %s, %s.", request.firstName, request.lastName);
return new ResponseClass(greetingString);
}
}Where RequestClass and ResponseClass are Java POJOs with beans (not including their definition here for brevity, see the documentation for the full implementation.) This also works out of the box because AWS is using Java beans for JSON serialization/deserialization. Our handler function here would be example.HelloPojo.
How would we implement this in Scala? Before getting there, let’s ask ourselves how we would define handle method in plain Scala. Handler is a function that takes an input and the context, does some actions and returns an output. So the Scala way to define a handler will be:
def handler[T, R](input: T, context: Context): RAs long as we can deserialize input JSON into type T and serialize output R into JSON, we should be good. And the most natural way to represent those inputs and outputs in Scala would be to use case classes (if our input or output isn’t a primitive of course). There is a problem though, if we convert the POJO example to Scala and define RequestClass and ResponseClass as case classes it won’t work. Why? let’s say we define our RequestClass as:
case class RequestClass(firstName: String, lastName: String)The issue is that since the JSON deserializer uses Java beans it would expect RequestClass to have a default parameterless constructor. In our case class we know that we don’t have one. Scala compiler will generate a construct that takes firstName and lastName parameters and stores those in private variables. Hence, no default constructor there.
Back to were we started. We can implement those classes as plain classes instead of case classes, have a default constructor and define getters and setters. So we basically create a mutable class and we’ll be forced to pass it around in case we structure our code into multiple functions. Let’s stop right here, that’s not why we like to code in Scala, right?
Next option that AWS gives us is to have input as InputStream and output as OutputStream. It seems like a better alternative for us, since we’ll handle serialization/deserialization ourselves and in previous example we saw that the default serialization/deserialization was what got us into trouble in the first place. Let’s look at Java example from Amazon’s documentation again:
package example;
import java.io.InputStream;
import java.io.OutputStream;
import com.amazonaws.services.lambda.runtime.RequestStreamHandler;
import com.amazonaws.services.lambda.runtime.Context;
public class Hello implements RequestStreamHandler {
public static void handler(InputStream inputStream, OutputStream outputStream, Context context) throws IOException {
int letter;
while((letter = inputStream.read()) != -1) {
outputStream.write(Character.toUpperCase(letter));
}
}
}See the documentation. The example basically converts the input text to uppercase, and the way to execute this is to specify example.Hello as the handler (actually not sure that the handler method should be static there since class implements RequestStreamHandler).
Great, we’ll have to deal with Java’s streams now, and this on top of all the other things we have to take care of for Java projects. Quite painful when you just need to write “one function”.
Let’s get back to where we ideally wanted to end up:
def handler[T, R](input: T, context: Context): RSo what if we can create generic methods that deserialize JSON from the input stream into an instance of type T, serialize an instance of type R into JSON, and send it to AWS in the output stream. Once we have that, then we can create helper methods that will handle all the complexity and pass the execution to our handler function.
Solution
Let’s see how far I got with it implementing the template. To generate a new project from the template, run:
activator new <YOUR PROJECT NAME> scala-aws-lambda-seedHandler code
In the generated project you’ll have Main.scala file.
For your convenience, there is MySimpleHander object defined in case your function is just dealing with primitives:
object MySimpleHander extends App {
def handler(name: String, context: Context): String = s"Hello $name"
}To execute this, you use <YOUR PACKAGE>.MySimpleHander::handler as your handler for lambda.
It also generates MyHandler class when you need to get JSON and respond with JSON:
case class Name(name: String)
case class Greeting(message: String)
class MyHandler extends Handler[Name, Greeting] {
def handler(name: Name, context: Context): Greeting = {
logger.info(s"Name is $name")
Greeting(s"Hello ${name.name}")
}
}To execute this, you use <YOUR PACKAGE>.MyHander as your handler for lambda.
Note that the handler class extends Handler[T, R] abstract class. If your lambda doesn’t return anything, you can extend from Handler[T, Unit].
It also won’t be uncommon to make a web call, talk to the DB and do some IO form your lambda code. So there would most likely be functions for those that return futures, and the handler would be some aggregation of those into another future. For this use, cases extend FutureHandler[T, R] class and implement handlerFuture. If your handler doesn’t produce output, then extend FutureHandler[T, Unit] class.
Configuration
In Scala we’re used to storing library’s default configuration in reference.config. The template also generates Config.scala file with Config trait that loads the config and uses Ficus. Feel free to mix it into your implementations where configuration is needed.
Logging
AWS provides log4j adapter that sends logs to CloudWatch. The template includes log4j.properties in resources directory with necessary configuration for it also.
Package and Upload to S3
The template is using sbt-assembly SBT plugin. To create the deployment package, run sbt assembly.
The output jar file is going be pretty large (like 32 Megabytes), so uploading it via AWS Lambda Console wouldn’t be a good idea. Instead, a much better alternative would be to upload to S3 and in AWS Lambda Console put the S3 url. The template handles this for you also, just run sbt s3Upload. Note that s3Upload sbt task is dependent on assembly task, so you can just run s3Upload and you’ll be good to go. Before doing S3 upload make sure you have AWS credentials properly set up (in ~/.aws/credentials or using IAM roles) and update build.sbt file to specify the S3 bucket:
host in upload := "<YOUR S3 BUCKET>.s3.amazonaws.com"The template uses sbt-s3 SBT plugin, so feel free to check out its documentation for more details on how to configure the S3 bucket info and AWS credentials.
Create AWS Lambda
Go to the AWS Lambda web page and press Create a Lambda function
Press skip in the following page since we’re not creating our lambda from a template AWS provides:
Press next in following page:

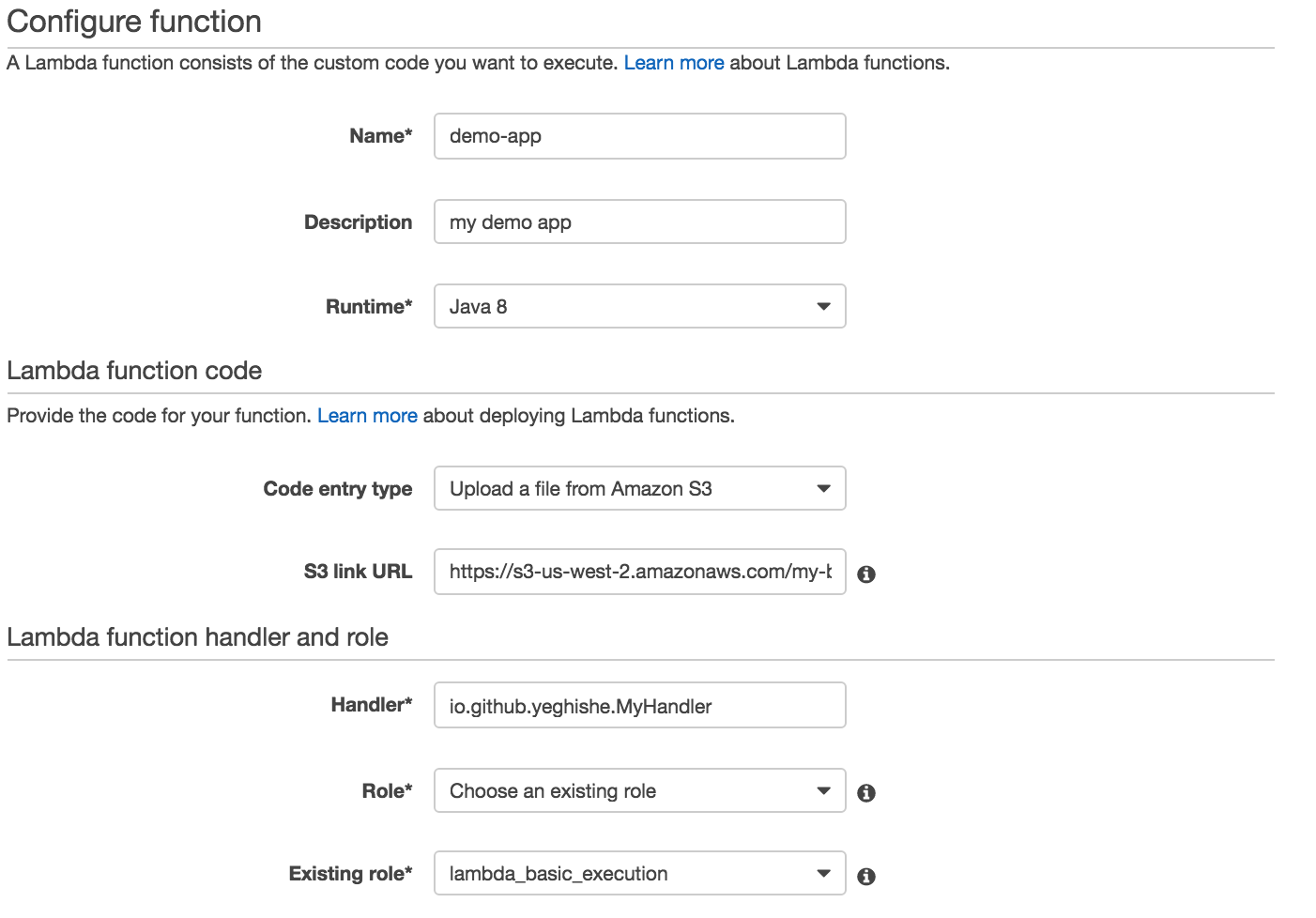
In the last page, specify your handler name and description, runtime as Java 8, chage the code entry type to S3, and change the S3 link url to be the url to the jar you uploaded with s3Upload task:
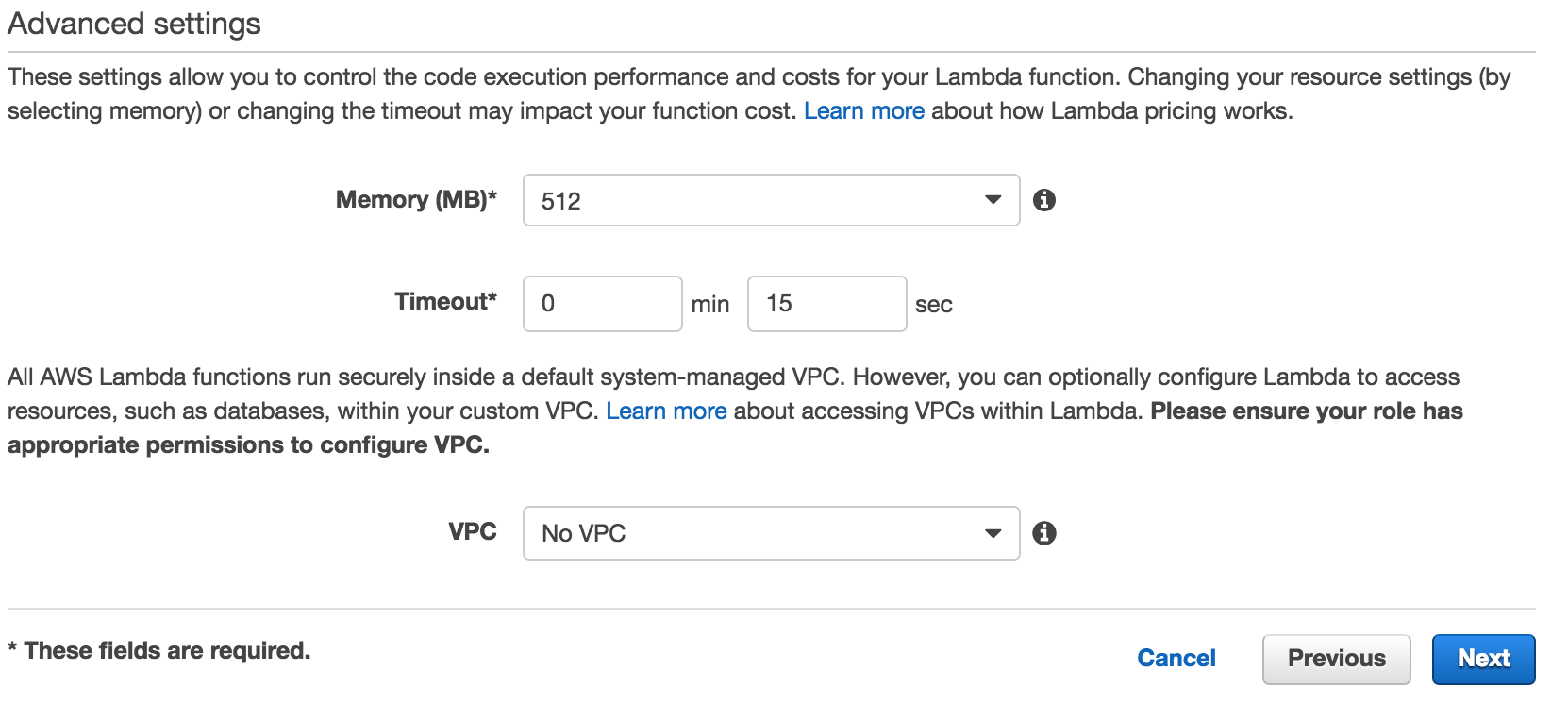
Specify memory, timeout, and VPC configuration:
We just created a lambda in Scala!
Performance
With AWS Lambdas, performance can be a concern if you’re running JVM. If it takes 1 second to start up JVM and 100ms to run your code, you’ll be billed for 1100 ms and that much will also be the latency. AWS Lambdas run in containers, so if the second time your code runs in same container, then you pay that penalty only on first run. If your use case is such that you won’t get much container reuse, latency is a concern, and/or you’re price sensitive, you may want to go with a non JVM language for your lambda.
I performed some tests to see how long it would take to start a container, as well as how much overhead would be added by my code handling the plumbing. Not a real load test (plus, I’m sure that there are so many variables in AWS Lambda infrastructure as well) but rather running it a couple times to get an idea.
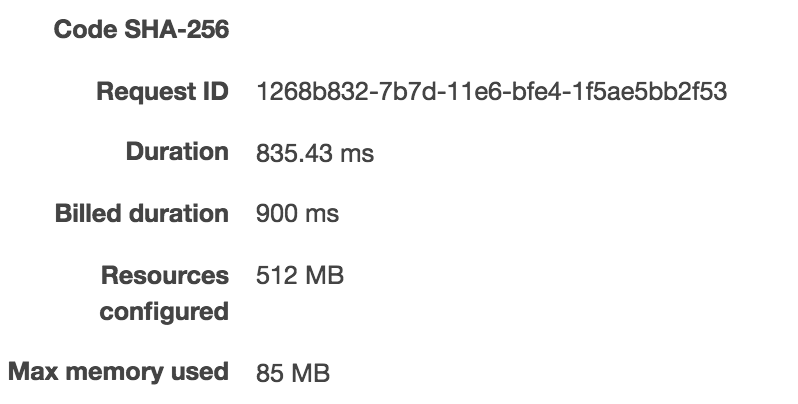
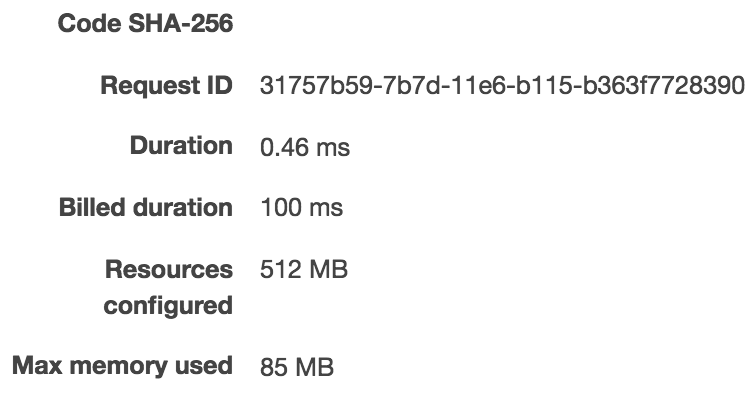
First, I created a lambda with simple handler which takes a string and returns a string (no JSON serialization/deserialization to do on our end.) Bellow are 3 exectuions of my lambda:
 |
 |
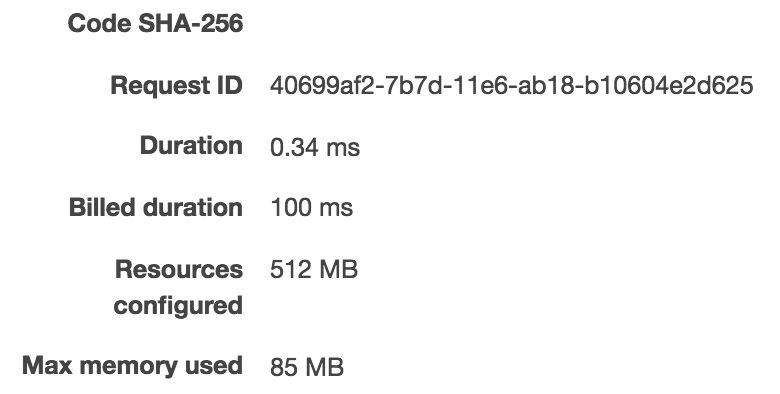 |
As we can see, it took 835ms to run it the first time, 0.46ms for the second time, and 0.34ms on the third 3rd run.
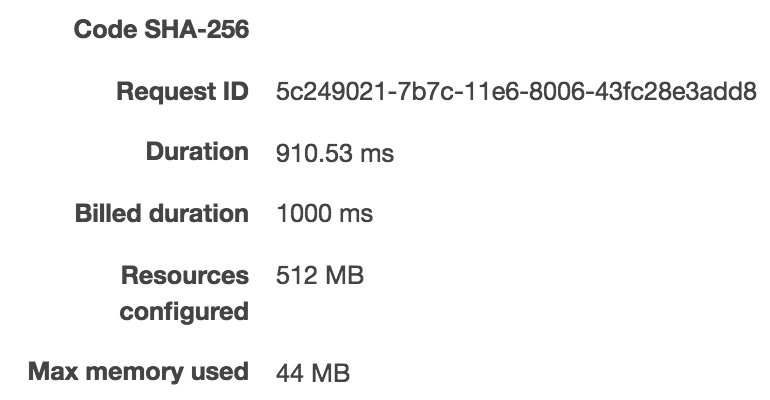
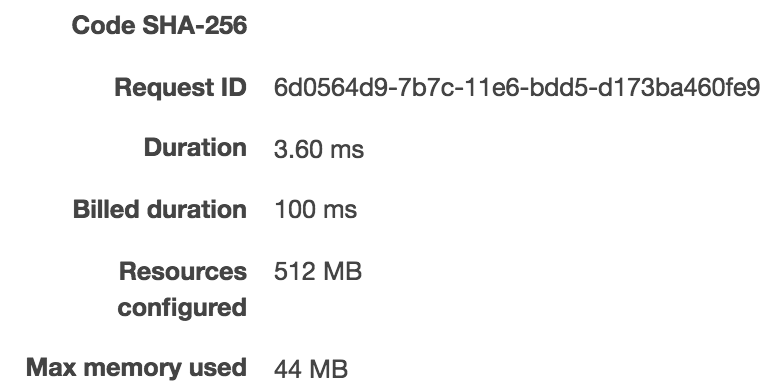
Next, I wanted to do the same thing with the Handler class implementation (here we do JSON serialization/deserialization on our end):
 |
 |
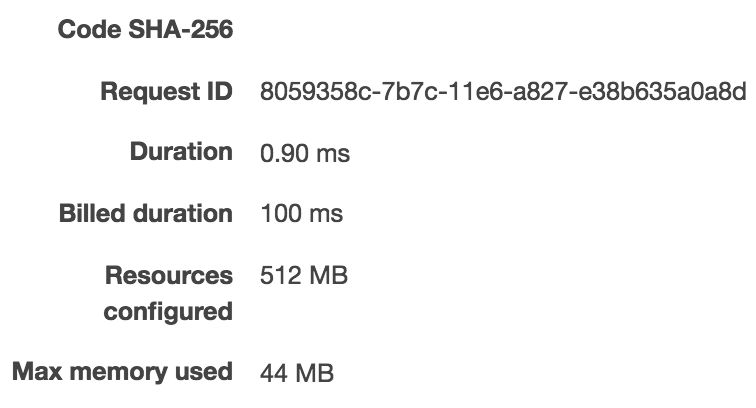 |
As we can see, it took 910ms to run it the first time, 3.6ms for the second time, and 0.90ms on the third 3rd run. As expected, this one is little slower than the implementation with only the primitives. But the conclusion can be made that the plumbing isn’t adding much overhead (less than 1ms), where I’m sure the actual handler code will take longer to execute and 1ms will be ignorable compared to the actual execution time.
Next, I wanted to create a lambda with the hello-world Nodejs template to get an idea about how much overhead JVM is adding:
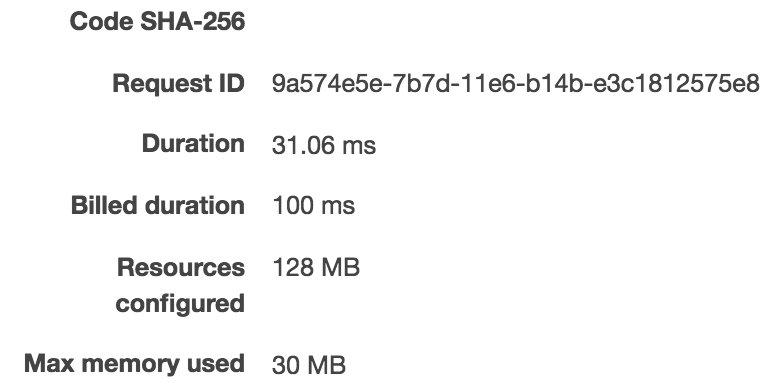 |
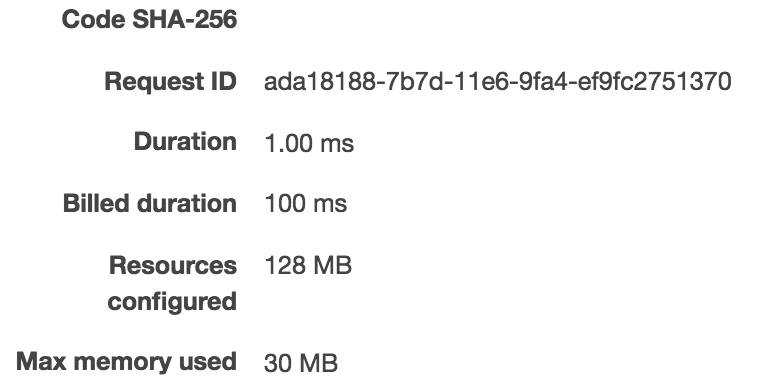 |
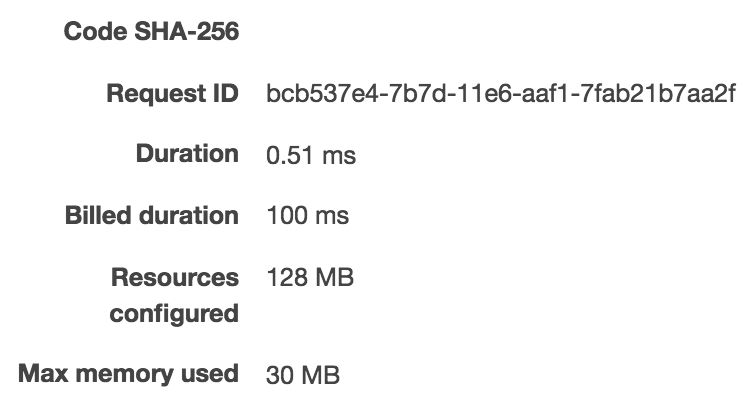 |
As we can see, it took 31ms to run it the first time, 1ms for the second time, and 0.51ms on the third 3rd run. You can notice that it takes about ~30ms to create a node container compared to ~900ms to create a JVM container. The execution time is about the same for both JS and Scala (all 3 under 1ms for 3rd run - note that I’m not load testing and also not trying to compare the Nodejs performance to the JVM performance.)
Another performance consideration which I didn’t capture would be when your container is being reused most of the time and your handler has been executed enough time. How much will JVM optimize execution time with JIT and other optimization it’s doing.
Source
Feel free to checkout github projects for the source:
Conclusion
We can create AWS Lambdas in Scala in a very elegant and easy way, using native language constructs,a and using great Scala tool chain without adding much overhead or boilerplate.
Hope you enjoyed reading the article and that you’ll consider using Scala when creating your next lambda ;)